World wide web is very wide network. If you know the web address or URL of a website you can find it easily by typing it in browser. But question is if you don’t know the URL, what will you do? How to find relevant results? Relax, no need to panic!! Search engine will help you to search a query.
Search Engine is a program or software system that allows users to search for information on the World Wide Web (WWW) by entering search queries into a search box. Search engines use regularly updated index to operate quickly & efficiently. Popular Examples of search engines are Google, Yahoo, & Bing.
How Search Engines Work
When a user enters a search query in search box like Google, search engines do several activities to serve the most relevant search results for a particular query. There are 4 key processes to deliver the search results to a user:
Crawling
Indexing
Determining Relevancy
Serving
All search engines go by this basic process when conducting search processes, different search engines use different algorithms, so they show different results depending on the criteria followed by each search engine.
#1. Crawling
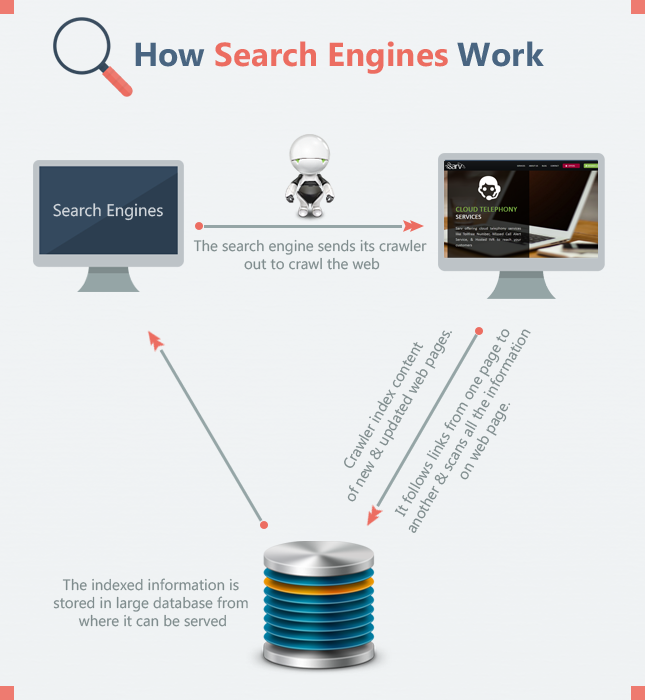
First, search engine crawl the web, it is the process by which search engines see what is there & discover new & updated pages. Crawler performed this task. “Crawler” is a piece of software & also called spider, example in case with Google, Googlebot is a crawler.
A crawler is an automated web browser, which follows links from one page to another & scans all the information on web page. Links allow the crawler to reach many billions of interconnected documents on the web. Crawler is indexing this information. Search engine crawlers can’t see images, videos & flash movies these are non-existent for them. So use “Alt tags” with images & give some description with videos to make it viewable for crawlers.
#2. Indexing
After web pages are crawled by crawler, the next process is indexing content of new & updated web pages. Every time a web crawler visits a web page, it makes a copy of it and adds its URL to an index. Once this is done, the web crawler follows all the links on the page, repeating the process of copying, indexing and then following the links.
Title tags, Meta tags, alt tags & links (active & dead links) are indexed in database. The indexed information is stored in large database from where it can be served.
#3. Determining Relevancy
To determine relevancy of web pages, each search engine have its unique algorithm. Due to these different algorithms, different search engines give different results in search engine result page (SERP) for same search query.
Some examples of Google’s algorithm are Page Rank, Google Panda, Google Penguin, & Hummingbird. Google gives more credits to websites, which have quality back-links. If you want good rank in search engine result page then make sure that search engine can index all the content on your site.
#4. Serving
While user enters a search query in search box, the search engine starts process. It searches their indexed pages in database, which match your search query. After this, it serves most relevant results among all the results in search engine result page (SERP) that match user’s search query.
Search engines show:
1. Results that are relevant & useful to searcher’s query.
2. Results according to the popularity of the websites serving the information.